
اتصالات وتقنية
مشروع BlenderBot من “ميتا” مثال على أهمية الاعتمادية والأمن لتقنيات الذكاء الاصطناعي وتعلّم الآلات


اتصالات وتقنية
أمنكس تدعم رؤية باير السعودية نحو مساحات العمل الذكية وتوفر حلولًا متطورة لقاعات الاجتماعات

اتصالات وتقنية
Samsung MENA Announces Dual-Agency Media Model Appointing Publicis Groupe and dentsu to Drive Media Excellence

اتصالات وتقنية
سامسونج الشرق الأوسط وشمال إفريقيا تعقد شراكة مع ‘بوبليسيس جروب’ و’دنتسو’ لتعزيز تميّزها الإعلامي
-

 أسواق5 years ago
أسواق5 years agoرد سي مول يُطلق حملة “الجمعة البيضاء” بالشراكة مع مجموعة واسعة من الماركات العالمية
-
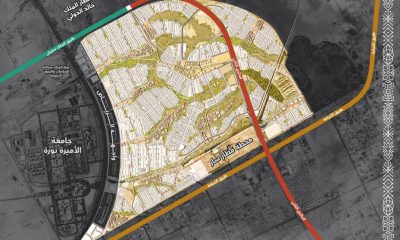
 عقارات5 years ago
عقارات5 years agoروشن تعلن عن حيّها الأول في مدينة الرياض
-

 سيارات5 years ago
سيارات5 years agoمجموعة تأجير تفتتح أول مركز صيانة سريعة لخدمة سيارات MG في المملكة العربية السعودية
-

 منوعات2 years ago
منوعات2 years ago“بي آر ويك” تختار إبراهيم المطوع ضمن أبرز المؤثرين في صناعة العلاقات العامة في الشرق الأوسط
-

 فن5 years ago
فن5 years ago“ماجد الفطيم” تفتتح دار “ڤوكس سينما” جديدة في “تاون سكوير” في جدة
-

 عطورات4 years ago
عطورات4 years agoالامير سعود بن فيصل يفتتح (فخامة نجد ) بالريتز كارلتون والذي تقيمه شركة ساري
-

 اتصالات وتقنية2 years ago
اتصالات وتقنية2 years ago“تي سي إل” تبرز ضمن أكبر 3 مصدّرين صينيين عالميين لأجهزة التكييف، تكشف النقاب عن تشكيلة جديدة من المكيفات لشهر رمضان المبارك في السعودية
-

 عطورات3 years ago
عطورات3 years agoسمو محافظ جدة يزور مصنع شركة عبدالصمد القرشي
You must be logged in to post a comment Login